Processori di Dinamica
Fader
A fader is any device used for fading, especially when it is a knob or button that slides along a track or slot. It is principally a variable resistance or potentiometer also called a ‘pot’. A contact can move from one end to another. As this movement takes place the resistance of the circuit can either increase or decrease.
Il fader è un componente che permette di applicare una dissolvenza (cross o a zero) ad un segnale audio.
Il crossfade (o dissolvenza incrociata) viene usata per creare una transizione morbida tra due traccie audio, una in uscita detta fade-out e una in entrata detta di fade-in. Questa dissolvenza ha tre parametri: durata, posizione e forma.
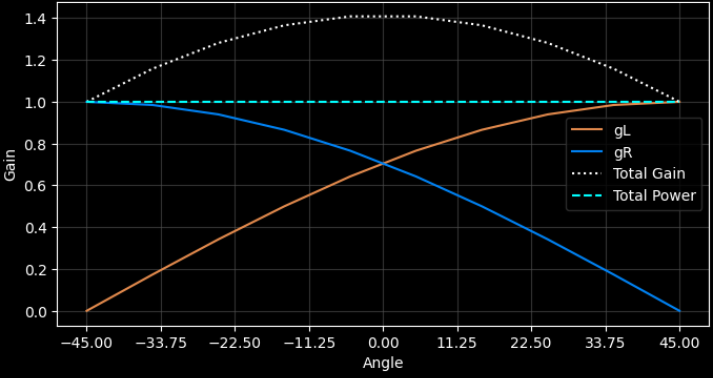
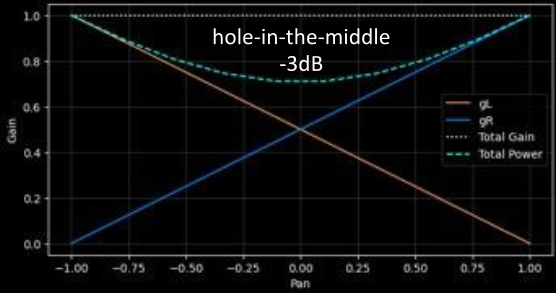
Quando si usa un crossfade lineare si ha un equal-gain, ovvero il gain totale è sempre uguale ad uno se una decresce linearmente e l’altra cresce linearmente.
Quando invece si ha un crossfade esponenziale si ha un equal-power.
Link to original
Equal Power Equal Gain Compressore
La compressione della gamma dinamica è un’operazione di elaborazione del segnale audio che riduce il volume dei suoni forti o amplifica i suoni bassi, riducendo o comprimendo così la gamma dinamica di un segnale audio. La compressione è comunemente utilizzata nella registrazione e riproduzione del suono, nella trasmissione, nel rinforzo del suono dal vivo e in alcuni amplificatori per strumenti.
Un’unità hardware elettronica dedicata o un software audio che applica la compressione è chiamato compressore.
Compressione sottrattiva Compressione additiva Il compressore non scala l’intero segnale, ma soltanto i campioni che attraversano la soglia (in dB). Viene usato molto per mantenere la dinamica in un determinato range standard per le pubblicazioni su piattaforme (Spotify, Youtube, Apple Music, etc…)
I parametri sono:
Link to original
- Threshold di ampiezza, ovvero la soglia da oltrepassare
- Ratio, ovvero di quanto scalare il suono
- Knee, ovvero se smussare o meno l’angolo nella zona di attivazione
- Attack time e release time, ovvero quanto tempo ci mette il compressore per applicare il ratio indicato
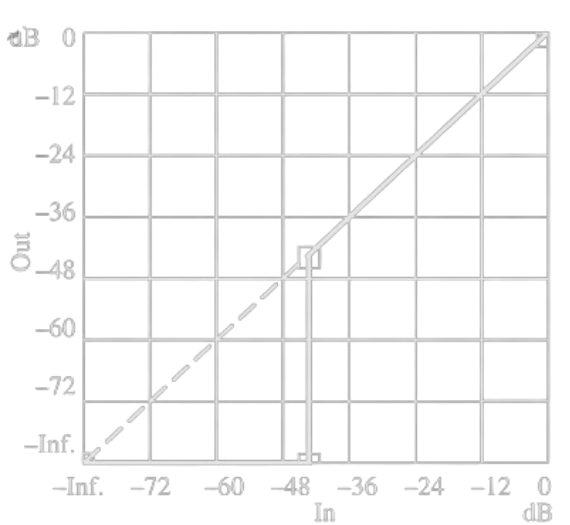
Limitatore
Il limitatore è un componente che taglia il segnale quando supera una determinata soglia di ampiezza (in dB).
Link to original
Si può considerare come un Compressore con una ratio molto alta (superiore a 10:1), un attacco immediato e un hard knee (spigoloso).Espansore
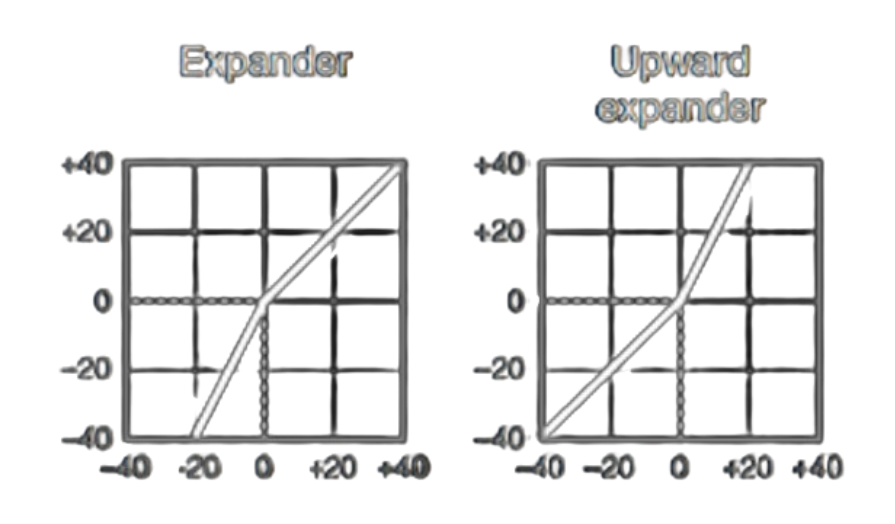
L’espansore è l’opposto del Compressore, ovvero riduce l’intensità dei suoni sotto la soglia e aumenta l’intensità dei suoni sopra la soglia.
Link to original
Link to originalNoise Gate
Il Noise Gate è un Espansore estremo che azzera i suoni con un’intensità minore della threshold.
Viene utilizzato per eliminare il rumore di fondo.Link to original
Stereofonia
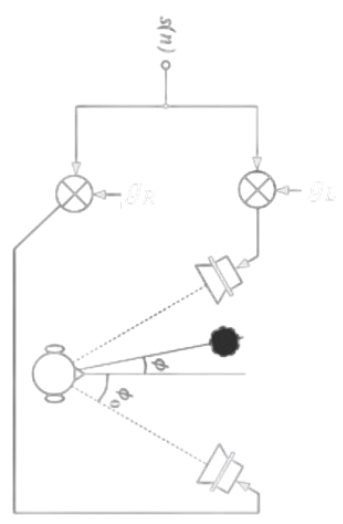
La Stereofonia è una tecnica di registrazione e di riproduzione del suono, che prevede due flussi informativi sonori separati (destro e sinistro), ognuno dei quali destinato ad essere riprodotto da un diverso altoparlante, che viene posizionato nell’ambiente d’ascolto in modo simmetrico e complementare rispetto all’altro e rispetto all’ascoltatore, secondo delle regole prestabilite da alcuni standard o linee guida.
La sterofonia si basa sul fatto che l’uomo possiede due orecchie e dunque una naturale attitudine della percezione uditiva a distinguere la provenienza spaziale dei suoni; per questo motivo, si contrappone alla monofonia, che prevede invece un unico flusso informativo sonoro.
L’uso della stereofonia permette di creare una sorgente sonora fantasma posizionata in uno dei punti della retta che unisce i due altoparlanti. I due altoparlanti devono riprodurre il segnale sincronamente.
Gli altoparlanti vengono posizionati ai vertici di un triangolo equilatero o rettangolo con terzo vertice l’utente in quello che viene detto sweet spot. Difatti, l’assunto della stereofonia è che l’utente del sistema sonoro si trovi nel punto che incrocia le normali di entrambe le casse, e orientato di circa 45° rispetto ad ognuna cassa.
Si possono spostare dei suoni nello spazio tramite l’operazione di Panning.
Link to original
Equalizzazione
Con Equalizzazione, nel campo del trattamento dei segnali audio, si indica l’operazione di livellamento delle varie parti dello spettro di frequenze che compongono un segnale audio.
L’equalizzazione viene usata per correggere difetti audio in specifiche bande sonore, rimuovere rumore o elaborare in maniera artistica il suono.
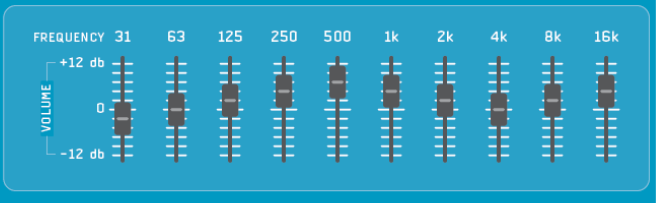
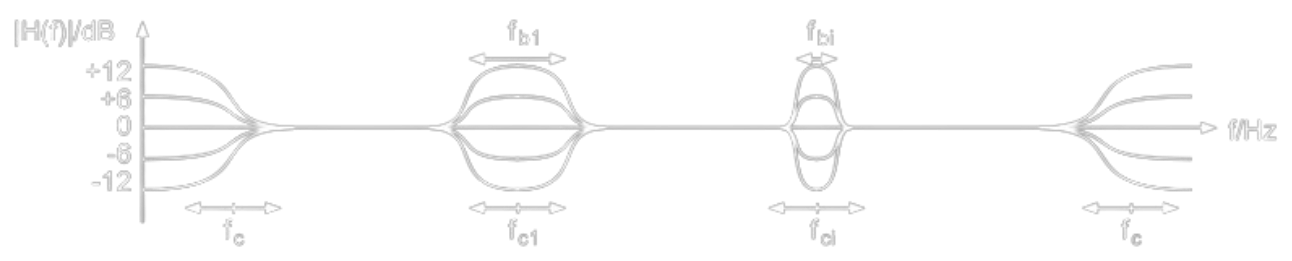
Equalizzatore grafico
Gli equalizzatori grafici sono i più semplici tra gli equalizzatori esistenti, dividono il range di frequenze 0-20k Hz in range fissi e permette di usare slider e manopole per l’equalizzazione.
Vedi anche: Equalizzazione
Link to originalEqualizzatore parametrico
L’equalizzatore parametrico utilizza diversi tipi di filtri per modificare il guadagno dei range stabiliti dal filtro.
Agli estremi si utilizzano dei filtri low/high Shelving Filter o pass, che sono unilateri. Nelle bande centrali si utilizzano invece filtri Peak Filter (o Notch filter, sinonimo)
Vedi anche: Equalizzazione
Link to originalEqualizzatore a fase lineare
Attenzione: articolo a bassa qualità
Link to originalA phase linear one Equalizer (Linear Phase EQ) is a special type of equalizer that aims to maintain the phase relationship between the different frequencies of a signal. A conventional equalizer can Phase shifts when it adjusts the frequency response of a signal. This means that the different frequency components of the signal experience different delays, which can lead to a change in the temporal structure of the signal.
A linear phase equalizer attempts to minimize or even eliminate these phase shifts.This can manifest itself in phase cancellations at the crossover point. The crossover point is the point in the frequency spectrum where the equalizer applies the High pass. These phase cancellations can last a few milliseconds or significantly longer and lead to audible frequency losses. Furthermore, this can happen stereo image change. The stereo image may widen or narrow.
Link to originalBanco di filtri in scala mel
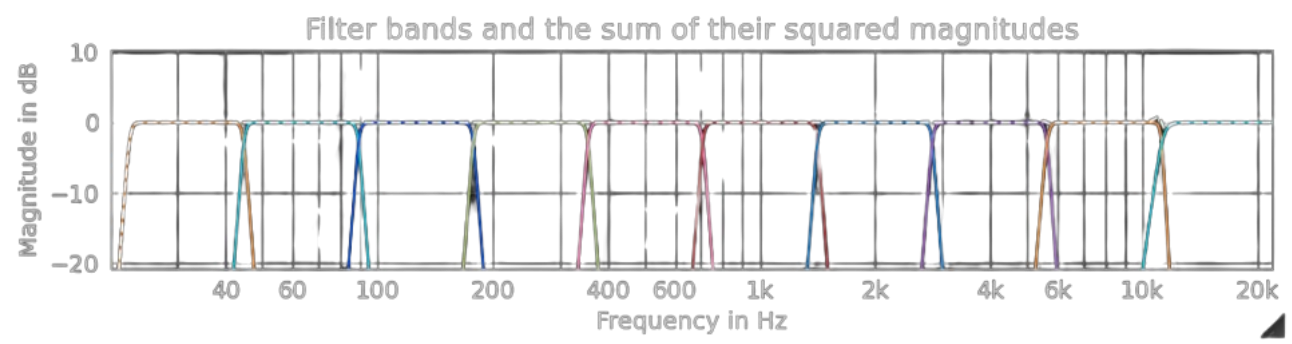
Il banco di filtri è un componente che viene utilizzato per fare equalizzazione di un segnale senza passare attraverso una DFT.
Questo prende un segnale in ingresso e lo scompone tramite diversi filtri in diverse bande di ottave, che possono essere amplificate o attenuate singolarmente.Warning
A differenza della DFT il banco di filtro non è invertibile e non preserva l’energia del segnale.
I banchi di filtri generalmente utilizzano la Scala mel.
Link to original
Scala mel
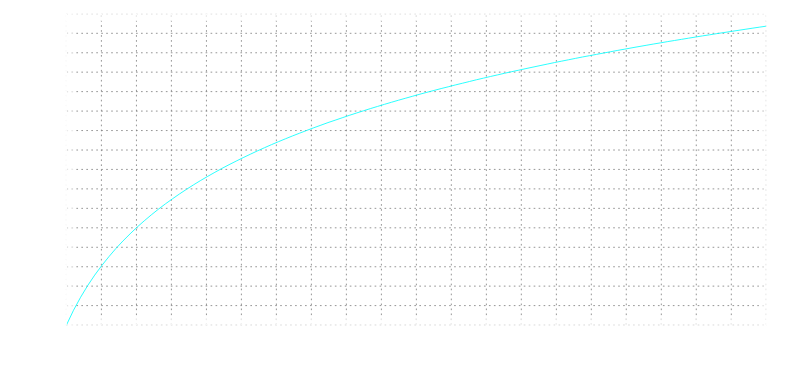
La Scala mel (dalla parola melody) è una scala di percezione dell’altezza (pitch) di un suono. È stata proposta da Stanley Smith Stevens, John Volkman e Edwin Newman nel 1937 nel Journal of the Acoustical Society of America.
La scala mel è una scala di altezze giudicate dagli ascoltatori uguali in distanza l’una dall’altra. Il punto di riferimento tra questa scala e la normale misurazione della frequenza è definito equiparando un tono di 1000 Hz, 40 dB sopra la soglia dell’ascoltatore, con un’intonazione di 1000 mel. Al di sotto di circa 500 Hz le scale mel e hertz coincidono; al di sopra di ciò, gli intervalli sempre più grandi vengono giudicati dagli ascoltatori per produrre incrementi di intonazione uguali.
Di conseguenza, quattro ottave sulla scala hertz superiori a 500 Hz sono giudicate come comprendenti circa due ottave sulla scala mel.
If everyone in the world had perfect pitch, then the Mel scale would make perfect sense. Instead, some people have untrained ears and so when they went to try to measure how accurately human ears could detect relative pitch differences using an arbitrary linear scale, different people gave different answers and in different ranges. The Mel scale is sort of the average shittyness of how well a random human ear can guess relative pitch difference.
Using 1000 as a starting pitch, they had people guess proportions of 1000 that they feel the next pitch they hear is different from that starting pitch. Like they literally played two pitches and a listener might guess that one pitch had “twice as much pitch” as the other. Thats how they made this scale in a nutshell. In principle, If all the listeners were trained or had perfect pitch, then every major 2nd they were given to listen to would have yeilded the same answer, and the Mel scale would be perfectly linear in all ranges.
I’ll give an example of an arbitrary linear mapping to illustrate the idea:
Suppose the pitch of C4 was a 5, then let C5 be 6, C6 be 7 and so on. In this scale, C5 is 1 more unit of pitch than C4.
Voila. I have now converted diatonic pitches to a linear scale. If we then convert diatonic pitches to frequencies, we would then have that 5 → 261.63Hz, 6 → 523.25Hz, 7 → 1046.50Hz. With this scale we could calculate A3’s value to be (5 / 261.63Hz) * 220Hz = 4.204This is what the Mel scale is doing to physical pitches in a basic sense. Except instead of just mapping octaves to integers, it maps frequency through a touchy feely I-Guess-This-Is-Right method that one of the studies roughly came out to the following logarithm.
Link to original
Scala d'ottava
La scala d’ottave è una scala determinata dalle frequenze delle ottave musicali. Il primo Do (C) ha frequenza 16.35Hz e i campioni successivi sono in multipli di questa frequenza fondamentale secondo la formula , quindi 16.35Hz, 32.7Hz, 65.4Hz, 130.8, etc…
Nei banchi di filtri talvolta si possono usare filtri che invece di usare scala mel utilizzano filtri centrati nelle frequenze delle ottave e di larghezza esattamente un’ottava, incontrandosi a -3dB.
Link to original
Sintesi Sottrattiva
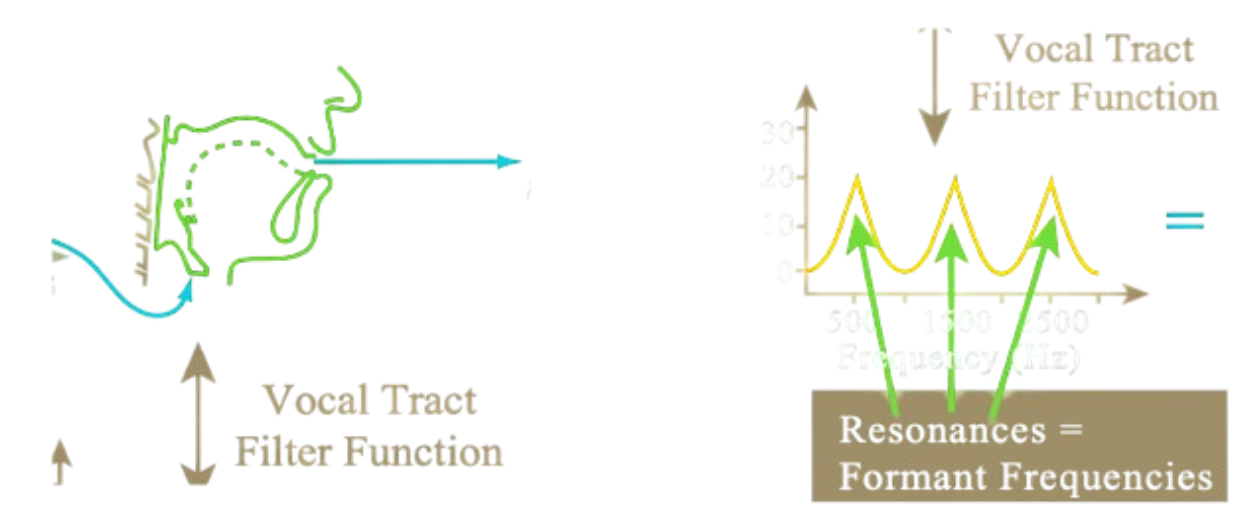
La sintesi sottrattiva è un modello di sintesi sonora, anche detto modello sorgente - filtro che prevede una sorgente sonora a cui viene applicato un filtro per modulare determinate frequenze sonore.
Questo deriva dalla modellazione del apparato vocale umano come:
- Corde vocali che agiscono come sorgente di un segnale a dente ad una frequenza fondamentale che stabilisce il pitch della voce.
- Cassa armonica del tratto vocale che agisce da cassa di risonanza o filtro per dare una forma specifica al segnale (fonema), ampliandolo attorno a delle frequenze dette Formante.
Questo modello può essere utilizzato per analizzare, riconoscere e sintetizzare il parlato umano e del parlatore.
Link to originalNOTE
Analisi Cepstrale
In teoria dei segnali, il Cepstrum è il risultato della trasformata di Fourier applicata allo spettro in decibel di un segnale. Il suo nome deriva dal capovolgimento delle prime quattro lettere della parola “spectrum”.
Il cepstrum di un segnale è la trasformata di Fourier del logaritmo della trasformata di Fourier del segnale. A volte viene chiamato lo spettro dello spettro.
dove x è il segnale, X il cepstrum, e F indica la trasformata di Fourier.
Algoritmicamente: segnale → trasformata di Fourier (FT)→ logaritmo → fase istantanea → trasformata di Fourier → cepstrumLe operazioni sul cepstrum vengono chiamate analisi di quefrenza.
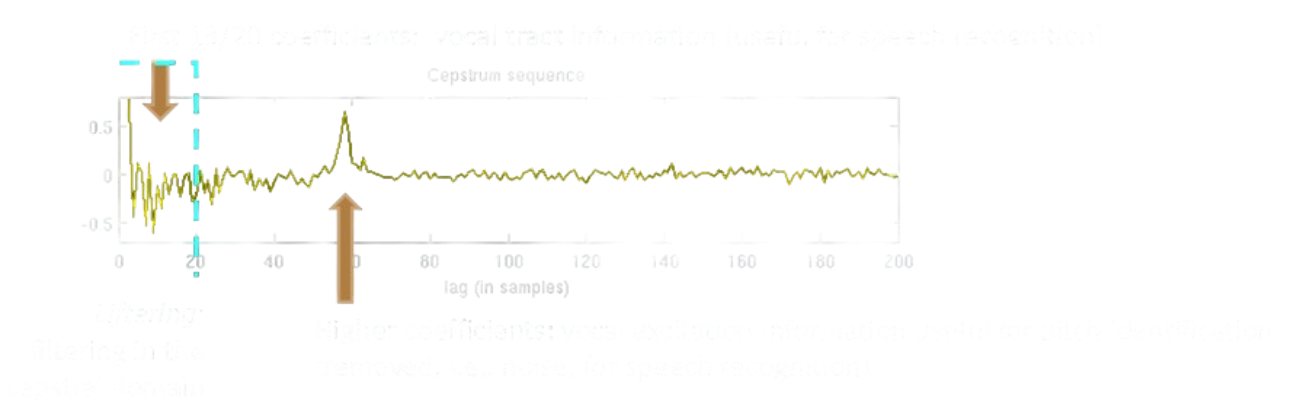
L’analisi cepstrale permette di separare le informazioni riguardo il pitch della voce e le formanti usate per generare il fonema pronunciato.
L’analisi cepstrale riesce a compattare / modellare la parte di tratto vocale nella prima quindicina di coefficienti cepstrali, mentre il pitch è identificato da un picco corrispondente ad un coefficiente in posizione molto più “lontana” e quindi facilmente individuabile/separabile.
Quindi applicando un filtro low-pass al cepstrum si riesce a ricavare il filtro applicato dalla cassa di risonanza e conseguentemente il fonema generato, mentre il rapporto tra il rateo di campionamento e la quefrenza di picco mostra la frequenza fondamentale della voce, che può ad esempio essere utilizzata per riconoscere il sesso della persona.
Link to original
Transclude of MFCC